




LatentHOI: On the Generalizable Hand Object Motion Generation with Latent Hand Diffusion.
Introduction
Hand-Object Interaction (HOI)是一个极具挑战性任务:手部自由度高、与物体接触状态复杂且动态变化,微小的不合理(如穿透、抖动、无接触)极易被察觉。
- 现有方法大多在训练中见过的物体上表现良好,但难以泛化到未见物体几何形状。
- 根本原因在于数据稀缺:
- 高质量 HOI 数据集规模小( GRAB 仅含 51 个物体、1.3k 序列),远小于人体动作数据集( AMASS 含344人、11.2k 序列)。
- 数据采集成本高、遮挡严重、标注困难。
尽管扩散模型在人体动作生成中取得成功,但直接将其用于HOI任务容易过拟合,导致在未见物体上生成穿透、抓握不合理或丢失物体等问题。多数现有工作假设物体是“已知的”,对未见物体泛化能力研究较少。
该文章提出LatentHOI,基于文本驱动来优化未见物体手-物交互运动生成效果。
- 核心思想:将生成任务解耦为:
- 高层时序运动(手与物体的全局轨迹)
- 低层空间抓握(每帧精细的手部姿态)
- 采用两阶段架构:
- GraspVAE:单帧条件变分自编码器,学习抓握的低维潜在表示。
- Latent Diffusion Model:在该正则化潜在空间中生成时序运动,避免直接在高维姿态空间扩散,从而提升泛化能力。
Related Work
Hand-Object Interaction Synthesis(手-物交互合成)
现有HOI合成方法主要分为两类:
(1) 运动学方法(Kinematic Methods)
- 基于监督学习,依赖大规模HOI数据集(如GRAB、DexYCB等)。
- 代表性工作:
- 使用条件变分自编码器(CVAE)(GOAL, Saga) 或隐式表示建模身手-物抓握。
- IMoS:根据意图和物体形状生成手-物运动,但假设初始抓握已知,且物体运动通过后处理添加,无法端到端联合生成。
- CAMS、GrIP:给定手或物体的全局轨迹,预测精细手部姿态;但依赖预设轨迹,泛化性受限。
局限:多数方法假设物体是训练中见过的,或需后处理估计物体轨迹,缺乏对未见物体的端到端泛化能力。
(2) 物理仿真方法(Physics-based Methods)
- 基于物理引擎和强化学习生成符合物理规律的交互。
- 代表性工作:
- D-Grasp:学习用MANO手模型抓取物体并移动到目标位姿。
- ArtiGrasp:扩展到可关节物体(如门、剪刀)。
局限:虽然物理指标更好,但生成质量通常低于运动学方法,且难以泛化到几何差异大的未见物体。
LatentHOI 端到端联合预测手与物体姿态,无需后处理,且在未见物体上表现出强泛化能力。
Grasp Generation(抓握生成)
聚焦于单帧抓握姿态生成(即给定物体,生成合理手部姿态):
- GrabNet:使用BPS(Basis Point Set)表示物体,通过粗粒度 VAE + 细化网络生成抓握。
- FLEX:利用身体与手部先验预测抓握。
- ContactOpt / Grasping Field:预测接触图或符号距离场(SDF),再通过优化或后处理解码出手部姿态。
- GraspTTA:使用 CVAE 建模手-物接触一致性。
LatentHOI的GraspVAE是单阶段、端到端的,不需要一致性模块,无需接触图或后优化,且左右手共享参数,提升数据效率。
Motion Diffusion Models(运动扩散模型)
扩散模型在人体运动生成中取得成功:
- MDM、MLD、MotionDiffuse:用于全身人体运动生成。
- HOI扩散模型(如HOI-Diff、InterDiff、CG-HOI):生成全身与物体交互(如搬椅子),但关注粗粒度动作,忽略手指级细节。
- MLD:在潜在空间中进行扩散以加速生成,但动机是效率而非泛化。
LatentHOI 也使用潜在扩散,但动机是解决数据稀缺下的泛化问题,专为高自由度手部与多样物体交互设计。
3D Hand-Object Interaction Motion Generation(3D手-物交互运动生成)
近期工作多沿用人体运动生成范式,采用多阶段设计:
- GeneOH Diffusion:三阶段生成手轨迹、空间关系、时间关系。
- InterHandGen:级联左右手扩散模型。
- Text2HOI:引入文本和接触图中间表示。
共同缺陷:大多在已见物体上评估,未系统测试未见物体泛化能力。
- DiffH2O:使用引导扩散提升物体泛化,但依赖参考帧。
- GraspXL:基于仿真 + RL 学习泛化抓握策略,需复杂模拟环境。
共同缺陷:依赖仿真环境和参考帧。
Method
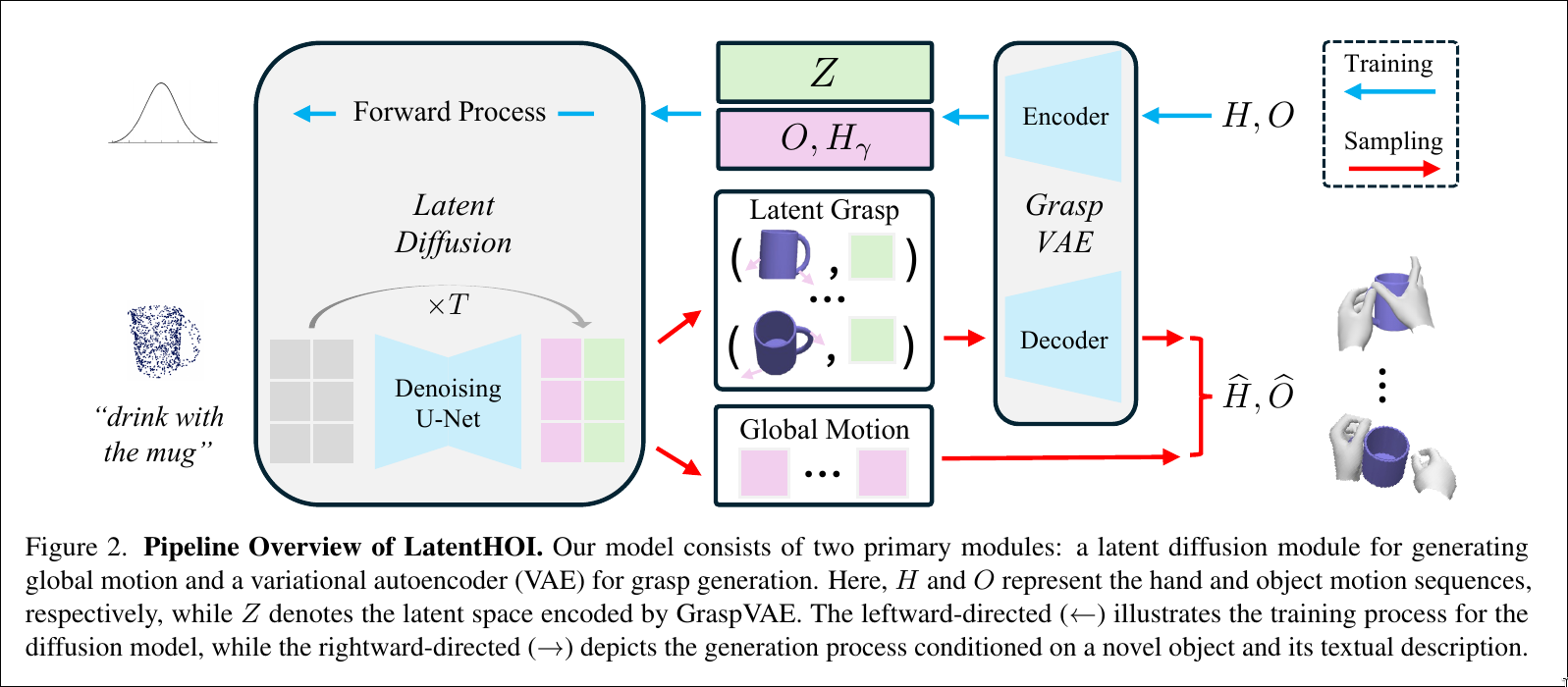
Problem Definition
- 输入:条件 ,包括:
- 物体的规范点云(canonical point cloud,如一个杯子的 3D 形状)
- 文本描述(text prompt,如 “drink from the mug”)
- 输出:生成长度为 帧的手-物交互序列:
- 手部姿态序列 (可为单手或双手)
- 物体 6D 位姿序列
表示方式
- 物体 :
- :6D旋转表示
- :平移
- 手部 :
- :MANO 模型参数(1个全局旋转 + 15个关节旋转),同样用6D表示
- :手根节点(手腕)位置,以物体为中心的相对偏移,实验证明此表示更稳定
- 条件编码:
- 文本 → CLIP 编码
- 物体点云 → BPS(Basis Point Set)编码
作者强调使用最小表示集(minimal set),不依赖 SDF 等冗余表示,仍能取得良好效果。
Decomposing Temporal and Spatial Generation(时空解耦)
动机
- 直接用扩散模型建模 在小规模 HOI 数据上极易过拟合,导致未见物体泛化差。
解耦策略
将生成分解为两部分:
- 高层(Temporal):手/物的全局轨迹(手腕和物体位姿)
- 低层(Spatial):每帧的精细手部关节姿态
引入潜在抓握代码 来编码每帧的空间抓握信息。
概率分解
- 第一部分 :由潜在扩散模型建模,生成时序轨迹和潜在代码。
- 第二部分 :由GraspVAE 解码器建模,逐帧生成精细手部姿态。
双重正则化机制
- 结构正则化:强制抓握生成依赖于物体位姿和手腕位置,形成条件依赖。
- 潜在空间正则化:在低维、正则化的潜在空间 中进行扩散,而非高维姿态空间,显著降低过拟合风险。
Two-staged Training(两阶段训练)
阶段一:训练 GraspVAE(单帧模型)
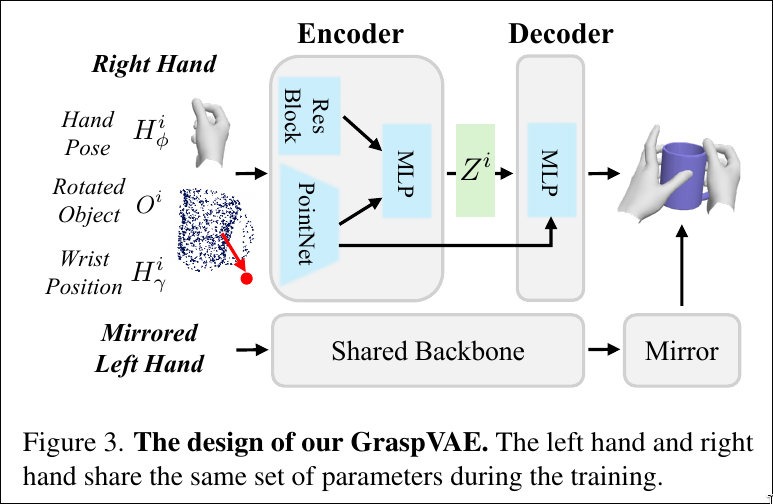
- 架构:标准 VAE,含编码器 和解码器
- 输入(编码器):
- 手部姿态
- 手腕相对位置
- 物体位姿 (通过将规范点云旋转对齐,并将 作为每个点的额外特征)
- 输出(解码器):重建
- 损失函数:
- :标准 VAE 证据下界(含 KL 散度正则化到标准正态分布)
- 额外加入手部网格顶点重建损失,提升几何精度
- 细节:
- 随机旋转增强:解决小数据集下的模式崩溃(mode collapse)
- 左右手共享参数:将左手数据镜像后与右手共享同一 VAE 骨干,缓解数据不平衡
阶段二:训练 Latent Diffusion Model(序列模型)
- 输入:冻结的 GraspVAE 编码器将训练集序列编码为
- 扩散目标:学习联合分布
- 潜在采样策略:
- 从编码器得到
- 采用 共享随机噪声:,其中 对所有帧共享
- 优势:促进潜在表示在时间维度上平滑过渡,生成更流畅运动
- 扩散目标函数(标准去噪损失):
- 采样时:使用 Classifier-Free Guidance 提升生成质量
Sampling(推理流程)
- 从标准高斯分布采样初始噪声
- 通过 T 步反向扩散,得到干净的
- 对每帧 ,将 输入 GraspVAE 解码器,得到
- 组合得到完整序列
Experiment
Dataset
-
GRAB(双手操作):
- 原始:51个物体,1.3k序列。
- 划分:47个物体用于训练,4个物体留作未见测试集。
- 序列从首次接触帧开始,下采样至20fps,统一截断/填充至160帧。
- 测试包含 17个(文本意图,物体)对。
-
OakInk(未见物体):
- 从其大规模物体库中人工挑选100个未见物体(20类),无任何训练数据。
- 将这些物体与GRAB中的文本配对,构成 212个测试对。
- 用于极端OOD(out-of-distribution)泛化测试。
-
DexYCB(单手抓握):
- 20个物体。
- 划分:16训练,4个未见物体测试。
- 序列从第1帧开始,填充至96帧。
所有模型仅在GRAB或DexYCB的训练集上训练,在未见物体上直接测试,不微调。
Baseline
- IMoS :需初始抓握帧,无法用于OakInk(无运动数据)。
- MDM :标准人体运动生成扩散模型,直接迁移到HOI。
- MLD :潜在扩散模型(用于全身运动),作为潜在空间对比。
- Text2HOI :文本驱动HOI生成。
Metrics
论文设计了一套物理合理性 + 多样性的综合指标:
| 指标 | 全称 | 含义 | 趋势 |
|---|---|---|---|
| IV | Interpenetration Volume | 手-物穿透体积(cm³) | ↓ 越小越好 |
| ID | Interpenetration Depth | 最大穿透深度(cm) | ↓ |
| CR | Contact Ratio | 接触顶点占比(%) | ↑ 越高越好 |
| IVU | IV per contact Unit | 单位接触面积的穿透体积(cm³/cm²) | ↓ 综合指标 |
| Phy | Physical Plausibility | 物体是否被“抬起”(Z>0)的接触帧比例 | ↑ 粗略物理合理性 |
| SD/OD | Sample/Overall Diversity | 生成样本的轨迹多样性(L2距离) | ↑ 避免模式崩溃 |
其中 IVU 是关键创新指标:单纯低IV可能因“手远离物体”导致,高CR可能因“严重穿透”导致。IVU = IV / 接触面积,能更公平衡量接触质量。
双手操作任务 (GRAB & OakInk)
| 数据集 | 模型 | IV ↓(穿透体积) | ID ↓(穿透深度) | CR ↑(接触比率) | IVU ↓(单位接触穿透) | Phy ↑(物理合理性) |
|---|---|---|---|---|---|---|
| GRAB(未见物体) | Real(真实动作) | 4.97 / 1.20 | 0.92 / 0.18 | 8.21 / 1.56 | 0.12 | 98.68 |
| IMoS | 10.38 / – | 1.25 / – | 4.61 / – | 0.53 | 84.88 | |
| MDM | 9.12 / 2.61 | 1.24 / 0.51 | 8.21 / 1.29 | 0.19 | 89.81 | |
| MLD | 9.62 / 3.14 | 1.06 / 0.49 | 10.23 / 0.87 | 0.24 | 85.68 | |
| Ours(LatentHOI) | 6.38 / 1.66 | 0.77 / 0.29 | 11.94 / 1.11 | 0.10 | 96.16 | |
| OakInk(极端OOD) | Text2HOI | 15.19 / 11.54 | 2.14 / 1.39 | 11.24 / 6.33 | 0.26 | 82.58 |
| MDM | 8.46 / 2.47 | 1.69 / 0.34 | 4.97 / 1.02 | 0.20 | 60.89 | |
| MLD | 9.15 / 4.25 | 1.79 / 0.56 | 5.36 / 0.77 | 0.29 | 46.41 | |
| Ours(LatentHOI) | 7.22 / 3.11 | 1.10 / 0.37 | 7.80 / 1.73 | 0.14 | 71.24 |
单手抓握任务 (DexYCB)
| 模型 | IV ↓ | ID ↓ | CR ↑ | IVU ↓ | Phy ↑ |
|---|---|---|---|---|---|
| GT(真实) | 5.89 | 2.38 | 9.91 | 0.12 | 96.30 |
| MDM | 7.78 | 2.10 | 8.87 | 0.18 | 86.22 |
| Ours(LatentHOI) | 7.70 | 2.01 | 11.98 | 0.13 | 88.52 |
Ablation Study
| 变体 | IV ↓ | ID ↓ | CR ↑ | IVU ↓ | 结论 |
|---|---|---|---|---|---|
| 完整模型 | 3.78 | 0.47 | 6.72 | 0.10 | — |
| VAE w/o 旋转增强 | 4.17 | 0.51 | 6.60 | 0.14 | 旋转增强防模式崩溃 |
| 扩散模型直接在姿态空间(w/o latent) | 4.99 | 0.60 | 6.53 | 0.13 | 潜在空间扩散更优 |
| 扩散使用独立噪声 | 4.51 | 0.51 | 6.52 | 0.12 | 共享噪声 提升平滑性 |
| 扩散使用均值 | 5.43 | 0.61 | 6.76 | 0.13 | 随机性对多样性必要 |