




Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
Introduction
- core bottleneck: datasets smaller than internet-scale LMM training data
- synthentic data 缺少 dexterous real-world hands
- human videos: abundant real-world data
Can we pretrain a dexterous VLA from large-scale human videos, analogous to GPT-3, to explicitly imitate human actions and adapt to robot hands via post-training?
challenge
- 数据异质性 (Data Heterogeneity)
人类视频数据来源广泛,拍摄设备、坐标系和录制条件差异显著。这种异构性使模型难以学习,需要设计统一的标准并嵌入 3D 空间推理能力。
- 手部量化 (Hand Quantization)
与机械夹爪等简单动作不同,手指动作复杂且精细。如何将连续手部运动离散化为“语言兼容”的表示,同时保留毫米级精度,是关键难题。
- 跨模态推理 (Cross-Modal Reasoning)
模型不仅要理解视觉场景和语言指令,还要准确映射到细致的手指运动。相比传统的多模态模型,这需要更高层次的多模态依赖建模。
- 机器人控制迁移 (Robot Control Transfer)
人手与机器人手在形态上存在差异,直接迁移不现实。因此必须通过精心的迁移学习,使学到的操作策略适配机器人平台
Being-H0
- physcial instruciton tuning
- 使用人类视频数据进行预训练
- 物理空间对齐
- post-training adaptation
Related Work
1. 大型多模态模型(Large Multimodal Models, LMMs)
- 视觉指令微调(visual instruction tuning) 是提升LMM指令遵循能力的关键技术。
- 当前顶级LMM多为闭源,但近期趋势趋向开放(如开源权重、训练细节和数据配方)。
2. 人体动作生成(Human-body Motion Generation)
- 介绍了从早期数据集(如KIT-ML、AMASS)到大规模文本标注数据集(如HumanML3D、MotionX、MotionLib)的演进。
- 主流方法分为两类:
- 扩散模型:擅长生成高保真动作,但可能缺乏物理合理性(如脚部滑动);
- 自回归模型:适合长序列建模和文本推理,常结合VQ-VAE、残差量化(RQ)等离散化技术。
- 近期工作尝试结合强化学习(RL)提升动作的物理真实性。
3. 手部动作生成(Hand Motion Generation)
- 聚焦于手-物交互(hand-object interaction)和精细动作精度。
- 现有数据集多依赖动作捕捉(mocap)或多相机系统,场景多样性受限(多为桌面操作)。
- 单目重建技术(如HaMeR)和3D手部模型(如MANO/SMPL-X)使从第一人称视频中提取伪标签成为可能。
- 但这些方法常受限于弱透视假设,难以泛化到视角变化大的场景。
- 最新工作(如Dyn-HaMR)通过结合SLAM解决相机运动问题。
4. 从人类视频中学习视觉-语言-动作模型(Learning VLAs from Human Videos)
- 当前VLA模型(如RT-1/2、OpenVLA、π0、GR00T)主要依赖小规模遥操作数据集(如Open X-Embodiment)或仿真数据。
- 遥操作数据规模小、成本高,尤其对灵巧手;
- 仿真数据存在sim-to-real gap,难以部署到真实机器人。
- 利用人类视频是一种有前景的替代方案,已有工作尝试提取:
- 视觉特征(如R3M)、
- 3D感知先验、
- 交互知识(如抓取、接触点)。
- 但多数方法采用隐式对齐(如GR00T的潜在动作),未显式建模人-机器人动作映射。
- 少数工作尝试在视觉层面(如图像编辑)或动作空间(如统一人中心状态)进行对齐,但仍局限于简单夹爪,忽略手指级精细动作对齐。
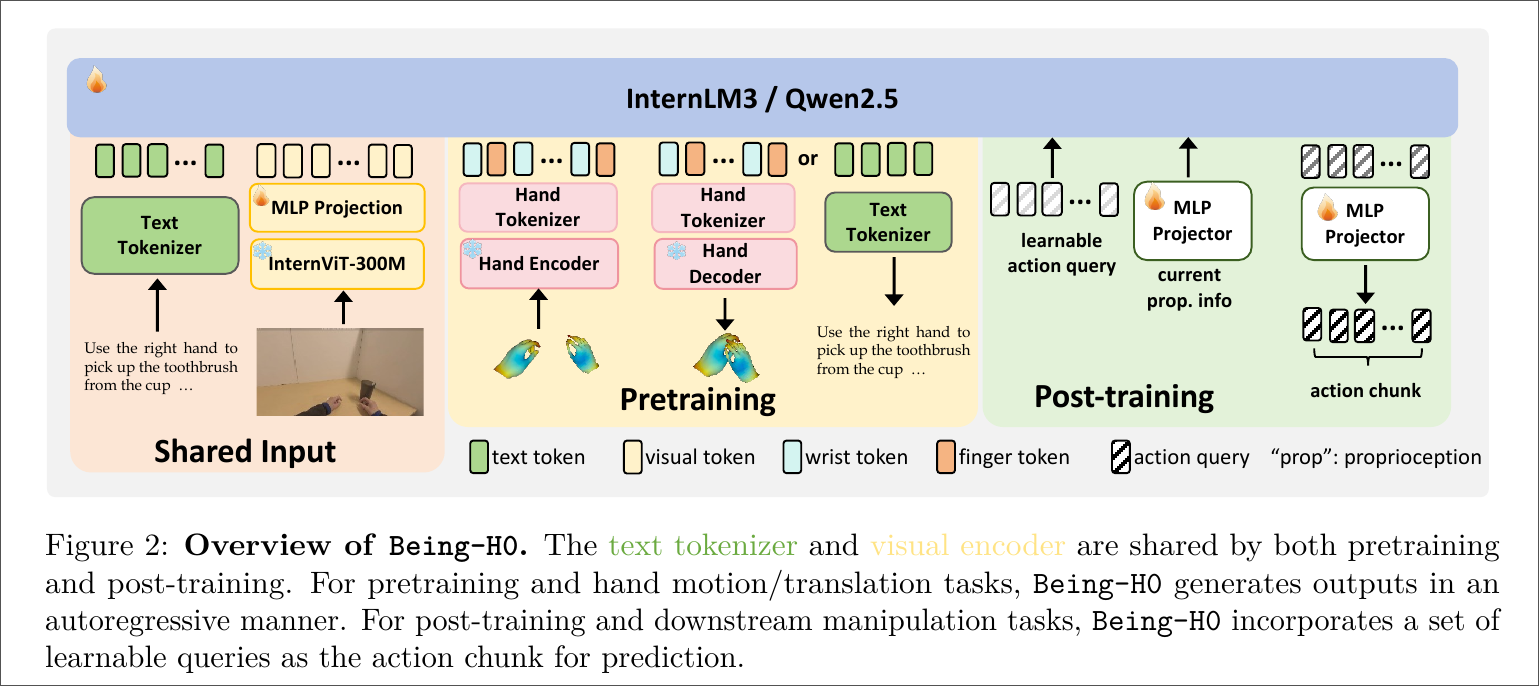
Overview
Pretraining
vision, language hand motion
数据集
优化目标
sample:
fundanmental model
target text and motion tokens
Physical Space Alignment
- 解决多源视频数据在相机内参、坐标系、3D感知缺失等方面的异构性
- 通过统一坐标系统与物理对齐,赋予模型3D空间推理能力
Post-training
- 将预训练好的基础模型适配到具体机器人任务
- 当前采用轻量 MLP 投影头 + 可学习动作查询(action queries) 的方式实现迁移
- 未来计划探索更复杂的迁移策略(如扩散策略、离散动作 token)
Challenge & Solution
1. 预训练数据构建困难(Pretraining Data Curation)
挑战:
当前机器人操作数据集(如 Open X-Embodiment、AgiBot)规模小、成本高,尤其缺乏手指级精细动作标注;而互联网上的人类视频虽规模大,但存在视角不一致、标注稀疏、相机参数异构等问题,难以直接用于训练。
解决方案:
构建 UniHand 数据集,通过以下策略整合异构数据源:
- 融合三类数据:动作捕捉(motion capture)、VR录制(如 Apple Vision Pro)、RGB 视频伪标注(使用 HaMeR 等模型估计 3D 手姿);
- 使用 MANO 参数标准化 所有手部动作;
- 采用 弱透视对齐(weak-perspective alignment)统一不同相机下的 3D 表示;
- 最终覆盖 150+ 任务、1000+ 小时视频、1.5 亿+ 指令样本。
2. 手部动作需高精度量化(Precise Hand Quantization)
挑战:
连续的手部动作(如 MANO 参数)需离散化以适配自回归语言模型架构,但传统量化方法易丢失毫米级精度,影响动作生成质量。
解决方案:
提出 Part-Level Motion Tokenization(分部件运动分词):
- 将手部分为 手腕(wrist)和 手指(fingers)两部分,分别建模;
- 基于 Grouped Residual Quantization(GRQ) 构建运动分词器;
- 引入 手腕重建损失项(Lwrist)提升全局位姿精度;
- 实现 毫米级重建误差,同时生成与 LLM 兼容的离散 token。
3. 多模态跨模态推理复杂(Unified Cross-Modal Reasoning)
挑战:
需联合建模视觉场景、自然语言指令与精细手部动作之间的复杂依赖关系,远比传统 LMM 的图文对齐更困难。
解决方案:
采用 统一自回归序列建模:
- 将图像 patch、文本 token、动作 token 拼接为单一序列;
- 使用 共享注意力机制(shared attention)实现跨模态交互;
- 视觉 token 替换
<IMG_CONTEXT>占位符,动作 token 用<MOT>...</MOT>包裹; - 模型可学习如“拿起牙刷” → 精确手指轨迹的映射。
4. 人-机动作迁移困难(Adaptive Robot Control Transfer)
挑战:
人类手与机器人手在自由度、形态、物理约束上存在差异,无法直接迁移动作。
解决方案:
设计轻量级 后训练(post-training):
- 冻结预训练主干,仅训练一个 MLP 投影头(MLP projector);
- 引入 可学习动作查询(learnable action queries)作为动作块(action chunk);
- 利用人类动作作为 先验知识,指导机器人控制;
- 实验证明该策略显著提升 数据效率 与 泛化能力
Physical Instruction Tuning
Pretraining
Model Architecture
- Visual Encoder: InternViT-300M
- projector: 2-layer MLP
- 每个时刻处理 image-text 对,预测手部运动序列
- 参考 《How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.》 使用动态高分辨率策略
- 参考 《Scaling large motion models with million-level human motions.》,在 LMM 中无缝链接手部动作(使用 VQ )和
<MOT>token
Hand Motion Tokenization
motion feature
1. MANO-D51
- 维度:51
- 组成:
- 关节角(finger joint angles):
- 表示为轴角(axis-angle)形式,共 15 个关节 × 3 维 = 45 维
- 手腕旋转(wrist rotation):
- 轴角形式,3 维
- 手腕平移(wrist translation):
- 3D 位置,3 维
- 关节角(finger joint angles):
- 总维度:45 + 3 + 3 = 51
- 特点:
- 轴角表示简洁,适合大角度旋转(如手腕);
- 但在手指精细旋转上存在数值不稳定性(如万向节锁问题)。
2. MANO-D99
- 维度:99
- 组成:
- 关节角:使用 6D 旋转表示(6D rotation representation),15 × 6 = 90 维
- 手腕旋转:6D 表示,6 维
- 手腕平移:3 维
- 总维度:90 + 6 + 3 = 99
- 特点:
- 6D 旋转是连续、无奇点的表示,更适合建模 精细手指动作;
- 数值更稳定,利于神经网络学习;
- 但对大角度旋转(如手腕)可能不如轴角紧凑。
3. MANO-D109
- 维度:109
- 组成:
- 在 MANO-D99 基础上,增加手部形状参数 β(shape parameters)
- β ∈ ℝ¹⁰,描述个体手型差异(如胖瘦、长短)
- 总维度:99 + 10 = 109
- 特点:
- 理论上更完整,但实验发现 引入 β 会降低动作生成性能(见 Table 6);
- 原因:形状变化在短时动作中影响小,反而增加噪声;
- 因此,Being-H0 在训练中 固定 β 为序列首帧值,仅建模动作动态。
4. MANO-D114
- 维度:114
- 组成:
- 基于 MANO-D51(轴角表示);
- 额外加入 21 个关节点的 3D 位置(joint positions):21 × 3 = 63 维
- 注意:关节位置 仅用于训练时的辅助监督(auxiliary loss),推理时不使用
- 总维度:51(原始)+ 63 = 114
- 目的:
- 通过关节位置提供几何约束,提升重建质量;
- 尤其有助于提升 相对姿态精度(PA-MPJPE)。
5. MANO-D162(Being-H0 最终采用)
- 维度:162
- 组成:
- 基于 MANO-D99(6D 旋转);
- 同样加入 21 个关节点的 3D 位置(63 维)
- 总维度:99 + 63 = 162
- 优势:
- 6D 旋转 → 更好建模手指精细动作;
- 关节位置辅助 → 提升几何一致性;
- 实验表明:虽然整体 MPJPE 略高于 MANO-D114(因手腕用 6D 不如轴角),但在 语义对齐(M2T R@3)和 生成质量 上表现最佳。
- 结论:模型更关注 功能性动作语义 而非绝对手腕位置,因此选择 MANO-D162。
补充说明:为何混合表示(手腕用轴角 + 手指用 6D)未被采用?
论文提到:
“We will explore the combination of axis-angle feature for wrist and 6D rotation for fingers in future work.”
说明作者意识到 混合表示可能更优(手腕用轴角,手指用 6D),但当前实现为统一表示,未来将探索更精细的分部件参数化。
总结对比表
| 表示方式 | 旋转表示 | 包含 β? | 包含关节位置? | 总维度 | 适用场景 |
|---|---|---|---|---|---|
| MANO-D51 | 轴角 | 否 | 否 | 51 | 手腕主导任务 |
| MANO-D99 | 6D | 否 | 否 | 99 | 手指精细动作 |
| MANO-D109 | 6D | 是 | 否 | 109 | 完整建模(但性能下降) |
| MANO-D114 | 轴角 | 否 | 是(辅助) | 114 | 几何约束强 |
| MANO-D162 | 6D | 否 | 是(辅助) | 162 | Being-H0 最终选择 |
这种对 MANO 表示的细致分析,体现了 Being-H0 在 动作建模精度 与 语义泛化能力 之间的权衡设计,是其实现毫米级手部动作生成的关键基础之一。
Grouped Residual Quantization
GRQ (Grouped Residual Quantization) 架构
GRQ 是一种先进的向量量化技术,旨在提高量化表示的表达能力和重建精度。
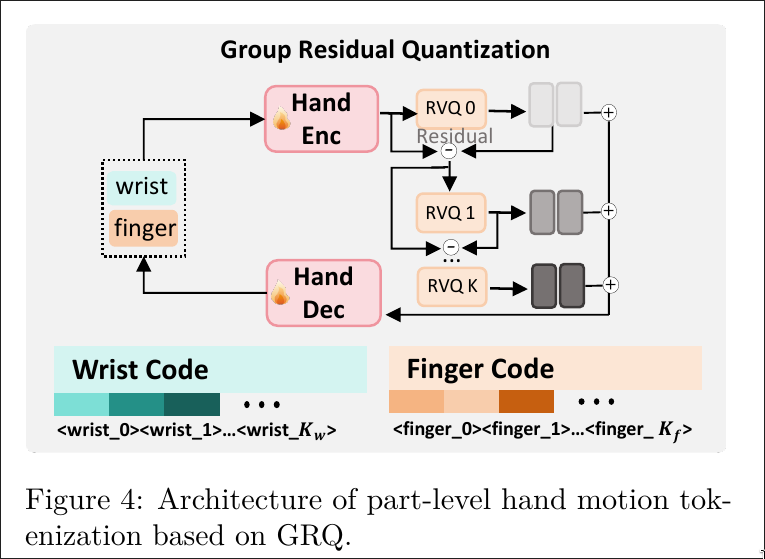
- 基础结构:它基于 残差向量量化 (Residual Vector Quantization, RVQ)。RVQ 通过多层 codebook 来逐步逼近输入特征。第一层捕捉主要信息,后续层则对前一层的残差进行编码,从而实现更精细的表示。
- 分组 (Grouping):首先,将编码器输出的特征图 的 通道维度 (channel dimension) 划分为 个独立的组,,论文中默认 (运动幅度大、模式相对简单的手腕,和运动精细、复杂的手指)。
- 独立量化 (Independent Quantization):对每个组 ,独立地应用一个完整的 RVQ 量化器。
- 优势:这种分组策略允许模型为特征的不同语义部分学习专门的量化表示,从而提高了整体的表达能力。
Part-Level Motion Tokenization
手部动作 拆分
- 手腕
- 手指
分开进行 tokenization
Multimodal Integration
- 文本 Token
- 处理方式与标准的大型语言模型(LLM)完全相同。
- 使用标准的文本分词器(如 BPE)将输入的指令或问题转换为文本 token。
- 视觉 Token
视觉信息的处理借鉴了 InternVL 的设计,并做了动态适配:
- 动态分块(Dynamic Patching):为了处理不同分辨率和内容复杂度的图像,模型会将输入图像动态地分割成 N 个图像块(patches)。
- 保留全局上下文:除了细节块,还会生成一个下采样的缩略图(thumbnail),以保留图像的全局语义信息。
- 编码与投影:这些图像块通过一个预训练的视觉编码器(InternViT-300M)提取特征,然后通过一个 MLP 投影层映射到与文本和动作 token 相同的嵌入空间。
- 结构化标记:视觉 token 序列被包裹在特殊的边界标记
<IMG>和</IMG>之间。在输入序列中,有一个占位符<IMG_CONTEXT>,在实际处理时会被真实的视觉 token 序列动态替换。
- 动作 Token
动作信息(即手部运动)通过 Part-Level Motion Tokenizer(基于 GRQ)进行处理
- 离散化:连续的 3D 手部运动序列(MANO 参数)首先被 Part-Level Motion Tokenizer 量化为一系列离散的整数 ID。
- 嵌入:这些整数 ID 被映射到预定义的动作 codebook 中的嵌入向量。
- 结构化标记:与视觉 token 类似,动作 token 序列也被包裹在特殊的边界标记
<MOT>和</MOT>之间,形成一个清晰的“动作块”。 - 时序密度:动作块的密度为 每秒 128 个 token,这保证了对精细动作的高保真建模。
一旦所有模态都被转换为 token,它们就会被拼接(concatenated)成一个单一的、统一的输入序列 。
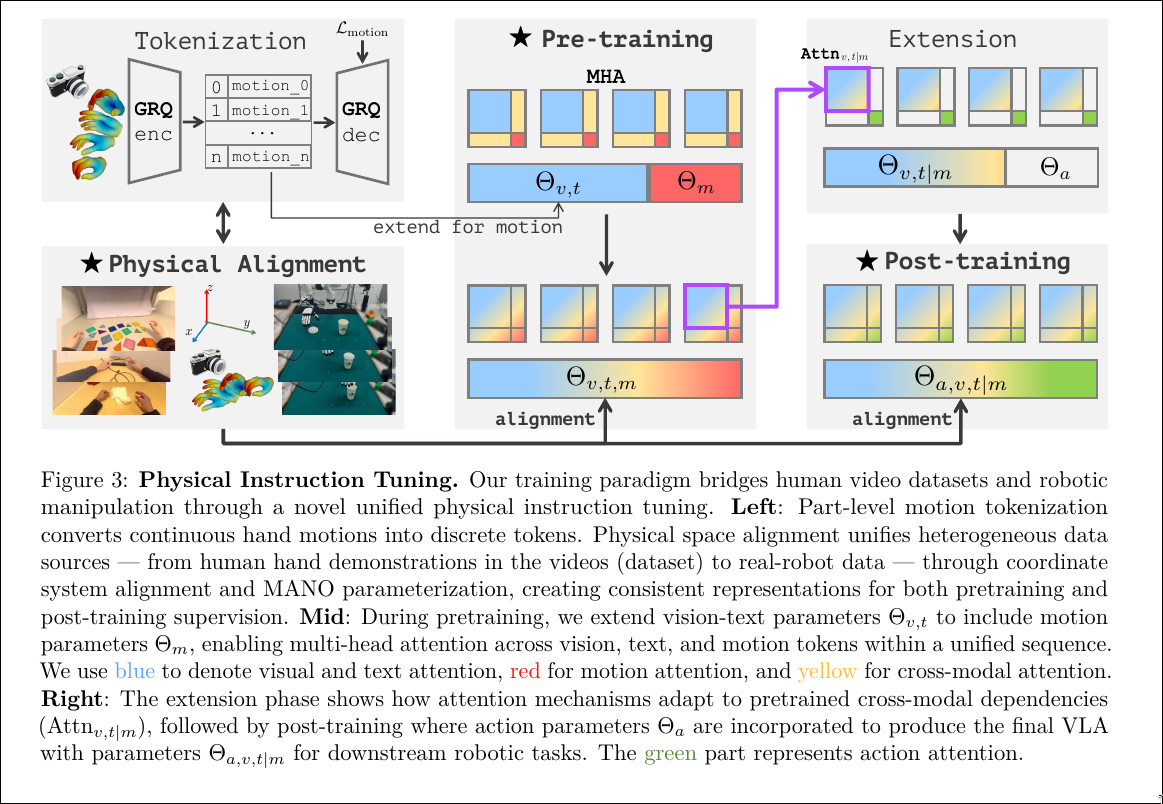
示例
假设输入是一个指令:“用右手从杯子里拿起牙刷”,并附带一张场景图片。
- 文本编码:“用右手…” 被文本分词器转换为一系列文本 token。
- 视觉编码:输入图片被动态分块、编码,并替换输入序列中的
<IMG_CONTEXT>占位符。 - 序列构建:模型接收到的完整输入序列可能如下所示:
[文本 token...] <IMG> [视觉 token...] </IMG> ... - 自回归生成:模型开始逐个预测下一个 token。在遇到需要生成动作的地方,它会先输出
<MOT>,然后预测一系列动作 token(这些 token 对应精细的手指和手腕运动),最后以</MOT>结束。 - 解码:生成的动作 token 序列被送入 Motion Tokenizer 的解码器,转换回连续的 MANO 参数,从而得到可执行的 3D 手部运动轨迹。
Dataset
UniHand 是迄今为止规模最大的以手部为中心的多模态指令数据集。其核心目标是解决现有机器人数据集中灵巧手操作数据稀缺的问题,通过整合异构来源,为模型提供海量、多样化的“视觉-语言-动作”三元组监督信号。
-
动作捕捉数据集(Motion Capture Datasets):
- 特点:在受控环境(如实验室)中使用多视角相机和传感器捕获,提供高精度的3D手部姿态真值。
- 代表数据集:OAKINK2(双手机器人操作)、HOI4D、H2O 等。
- 优势/劣势:精度高,但场景和任务多样性有限。
-
VR录制数据集(VR-Recorded Datasets):
- 特点:利用 VR 设备(如 Apple Vision Pro)的内置摄像头和 SLAM 技术,在更自然的环境中记录人手与物体的交互。
- 代表数据集:EgoDex(包含194种操作任务,如系鞋带、叠衣服)。
- 优势/劣势:兼具良好的3D真值和更高的场景多样性。
-
伪标注数据集(Pseudo-Annotated Datasets):
- 特点:利用现成的单目手部姿态估计算法(如 HaMeR)从海量的“野外”(in-the-wild)网络视频(如 Taste-Rob)中自动生成伪3D标签。
- 优势/劣势:可扩展性极强,场景和任务多样性最高,但标签存在一定噪声。
总体规模:
- 原始数据:聚合自11个基准数据集,包含 44.4万条任务轨迹,覆盖 1.3亿帧 视频,总计 超过1155小时。
- 指令数据:通过自动标注流程,生成了 超过1.65亿个 “视觉-语言-动作”指令对。
- 训练子集 (UniHand-2.5M):由于计算成本限制,论文从中采样了250万个高质量、任务和来源平衡的样本用于模型预训练。
数据处理流程
为了将这些异构数据统一为高质量的训练数据,论文设计了一套精细的数据处理流水线:
-
手部姿态标准化(Hand Pose Standardization):
- 目标:统一所有数据源的手部表示。
- 方法:将所有手部姿态统一转换为 MANO 参数(包含关节角度
θ、手腕旋转rrot、平移τ和形状β)。对于只有3D关节点的数据,通过优化反推MANO参数;对于只有RGB视频的数据,则使用 HaMeR 进行估计,并进行后处理(如左右手校正、时间平滑)以提高可靠性。
-
任务描述标注(Task Description Labeling):
- 目标:为原始视频-动作对生成丰富、结构化的语言指令。
- 方法:采用分层标注框架。
- 视频分块:将长视频分割为最长10秒的非重叠块。
- 两级标注:使用强大的视觉语言模型(Gemini-2.5-Flash-Lite)进行标注。
- 块级(Chunk-level):生成高层次的任务指令和摘要。
- 秒级(Per-second):生成更精细的指令和描述,包含接触状态、物体属性、手部细节等。
- 双手标注:分别标注双手的整体动作和单手动作。
-
指令数据生成(Instructional Data Generation):
- 目标:构建多样化的训练任务。
- 方法:基于上述标注,设计了三种核心任务模板,并使用 Gemini-2.5-Pro 生成大量变体:
- 指令式动作生成(Instructional Motion Generation):给定图像和指令,生成手部动作序列。
- 动作翻译(Motion Translation):给定图像和动作序列,生成文字描述。
- 上下文动作预测(Contextual Motion Prediction):给定历史动作、当前图像和指令,预测后续动作。
-
视角不变性(View-Invariant Motion Distribution Balancing):
- 目标:解决不同数据源因相机视角不同导致的分布偏差问题,提升模型泛化能力。
- 方法:对小规模数据源进行数据增强,但保持弱透视投影的一致性。
- 深度缩放(Depth Scaling):随机缩放手部在相机坐标系中的深度,并同步缩放图像。
- 平面内旋转(In-Plane Rotation):绕相机光轴旋转手部姿态和图像。
Experiments
主要分为 手部运动生成/理解 和 真实机器人操作 两大板块。
实验设置
- 模型规模:测试了 1B、8B 和 14B 三种规模的 InternVL3 主干。
- 评估数据集:从 UniHand 中保留了 5% 的数据作为测试集,并分为:
- Head Split:主要来自 EgoDex,代表常见、主导的运动模式。
- Tail Split:来自 TACO、HOI4D 等,代表长尾、多样化的运动模式,用于测试泛化能力。
- 评估任务:
- 视觉引导的手部运动生成(Visual-Grounded)
- 上下文手部运动生成(Contextualized)
- 手部运动翻译(Hand Motion Translation)
- 评估指标:
- 空间精度:MPJPE(关节位置误差)、MWTE(手腕平移误差)、PA-MPJPE(经Procrustes对齐后的误差)。
- 语义一致性:M2T R@3 / T2M R@3(动作-文本互检索准确率)、FID(动作分布相似度)。
- 结构有效性:Valid Rate(生成的动作块是否符合
<MOT>...</MOT>格式)。
实验结果
手部运动生成与翻译
- 模型规模效应:更大的模型(8B, 14B)在所有指标上均显著优于小模型(1B)和 baseline GR00T N1.5。这体现在更低的空间误差(MPJPE, MWTE)和更高的语义一致性(M2T R@3)。
- 泛化能力:Being-H0 在 Tail Split 上的性能提升尤为显著,证明了其从大规模、多样化数据中学习到的强大泛化能力。
- 结构化生成:大模型(8B, 14B)的 Valid Rate 接近或达到 100%,说明其能可靠地生成符合格式要求的动作序列。
长序列运动生成
- 挑战:随着预测时长增加(6-10秒),所有模型的误差都会累积增大。
- 优势:Being-H0(尤其是8B和14B)在长序列生成中依然保持了相对最优的性能,证明了其在时间上的连贯性建模能力。
消融实验
- Part-Level Motion Tokenizer 的优越性:与统一量化整个手部的方案(4-Groups, 16-Layers)相比,分开量化手腕和手指的方案在重建和生成任务上均取得最佳效果。
- MANO-D162 特征的有效性:尽管轴角(axis-angle)在整体重建误差上略优,但使用 6D旋转(6D rotation)的 MANO-D162 特征在下游生成任务中表现更好,因为它能更好地建模精细的手指动作。
- 数据配方的重要性:
- 视角平衡(w/o Balance):移除后,模型在 Tail Split 上性能大幅下降,证明了该策略对泛化至关重要。
- 辅助任务(w/o Translate/Context):移除动作翻译和上下文预测任务后,核心的运动生成任务性能也会下降,说明这些辅助任务能提供有价值的监督信号。
- 数据规模效应 (Figure 9):模型性能随着训练数据量的增加而稳步提升,验证了大规模数据的价值。
真实机器人实验
- 实验平台:Franka 机械臂 + Inspire 灵巧手 + RealSense 相机。
- 对比基线:
- GR00T N1.5:同样是基于人类视频预训练的 VLA,但采用隐式学习。
- InternVL3:与 Being-H0 架构相同,但没有进行手部运动预训练和物理对齐。
- 评估任务:包括抓取放置、操作铰链物体(工具箱、杯盖)、处理柔性物体(展开衣服)、精确控制(倒水)等。
- 关键结果:
- 成功率:Being-H0 在所有任务上均取得了最高的成功率。
- 泛化能力:在 Pick-Place-Toy 任务中,Being-H0 能成功处理未见过的物体和杂乱场景,而 GR00T 表现明显下降。
- 失败模式分析:InternVL3(无预训练)表现出典型的精度不足问题,如无法准确对齐杯盖、抓取不稳、操作高度错误等。而 Being-H0 则能执行稳健且精确的操作。
- 数据效率:Being-H0 仅用25%的演示数据,就能达到或超过基线模型(InternVL3)使用100%数据的性能。这极大地降低了真实机器人部署的数据收集成本。