




Reconstructing Hands in 3D with Transformers
Introduction
The key to HaMeR’s success lies in scaling up the techniques for hand mesh recovery. More specifically, we scale
both the training data and the deep network architecture
used for 3D hand reconstruction.
-
Training Data
- multiple available sources of data with hand annotations, including both studio/controlled datasets with 3D ground truth
- in-the-wild datasets annotated with 2D keypoint locations
-
Network: a large-scale transformer architecture
Benchmarking
HInt
- annotating hands from diverse image sources
- 2D hand keypoints annotations
- videos from YouTube
- egocentric captures
- controlled condition❌
- in-the-wild✔️
Related work
3D hand pose and shape estimation
- regress MANO parameters from images
- FrankMocap
- the vertices of the MANO
mesh - better align with evidence - failure with occlusions and truncations
Hand datasets
3D
- FreiHAND Captured in a multi-camera setting and focuses on different hand poses as well as hands interacting with objects.
- HO-3D and DexYCB Captured in a controlled setting with multiple cameras but focuses more specifically on cases where hands interact with objects.
- InterHand2.6M Captured in a studio with a focus on two interacting hands.
- Hand pose datasets Captured in the Panoptic studio and offer3D hand annotations.
- AssemblyHands Annotated3D hand poses for synchronized images from Assembly101, where participants assemble and disassemble take-apart toys in a multi-camera setting.
2D
- COCO-WholeBody Provides hand annotations for the people in the COCO dataset.
- Halpe Annotates hands in the HICO-DET dataset . Both of them source images from image datasets that contain very few egocentric images or transitionary moments.
- HInt
- images from both egocentric and third-person video datasets
- more natural interactions with the world
Technical approach
MANO parametric hand model
input
- pose
- shape
function
- the mesh of hand, vertices
- joints of the hand, joints
Hand mesh recovery
- image pixels() to MANO parameters
- regressor also estimates camera parameters
- project the 3D mesh and joints to 2D keypoints
- given camera intrinsics
final mapping:
Architecture
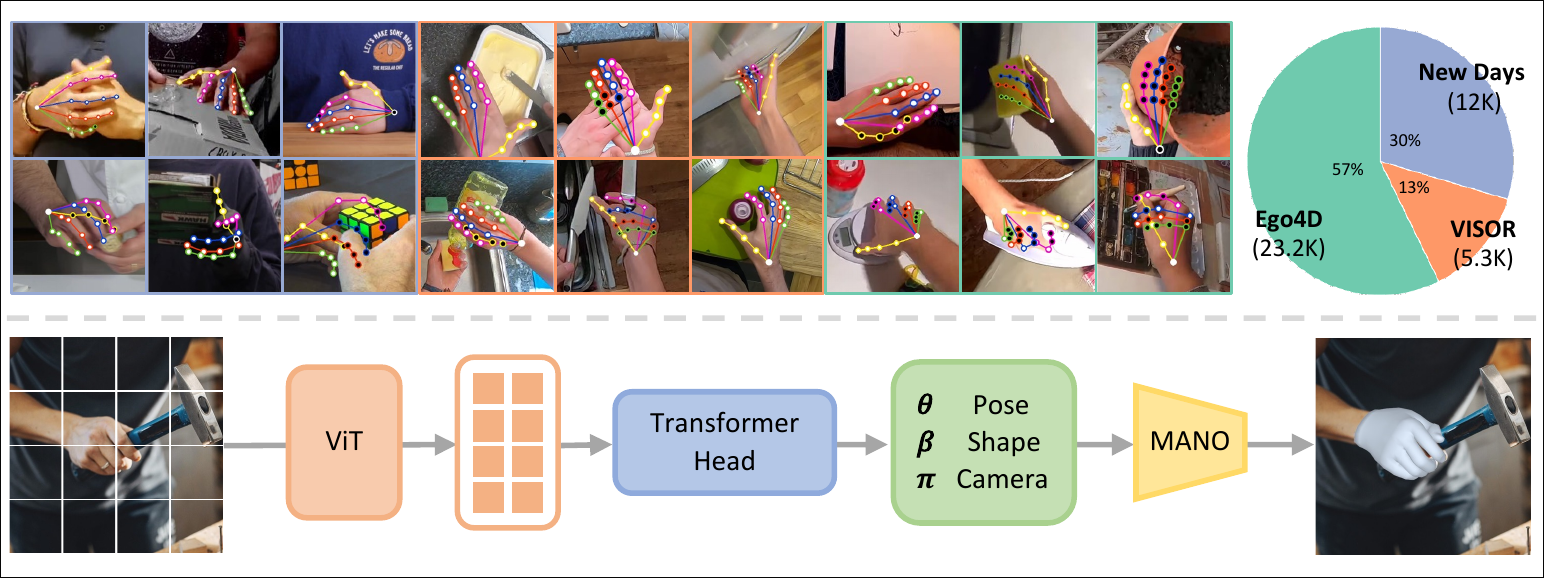
transformer head
- decoder that processes a single token while cross-attending to the ViT output tokens
- output
Losses
- discriminator , only 2D keypoints available
- hand shape
- hand pose
- each joint angle, separately
Training data
2.7M training examples
- 4x larger than FrankMocap
- mostly in controlled environments
- %5 in-the-wild images
HInt: and eractions in the wild
- annotates 2D hand keypoint locations and occlusion labels for each keypoint
- built off
- Hand23
- Epic-Kitchens
- Ego4D
- first to provide “occlusion” annotations for 2D keypoints
Experiments
3D pose accuracy
dataset
- FreiHAND and HO3Dv2: controlled multi-camera environments and 3D ground truth annotations
metrics
- PA-MPJPE and AUCJ (3D joints evaluation)
- PA-MPVPE, AUCV , F@5mm and F@15mm (3D mesh evaluation)
2D pose accuracy
dataset
- HInt
metrics
- reprojection accuracy
Ablation analysis
- Effect of large scale data and deep model
- Training with HInt