




Mixture of Contexts for Long Video Generation
Introduction
challenge
- transformer 生成长视频的计算和内存成本高
- 准确地利用长上下文记忆以确保时空一致性
Mixture of Contexts (MoC) framework:每个询问token“动态”选择最相关的上下文块进行注意力计算
- 使用 Adaptive Mixture of Contexts (MoC) 替换标准的全注意力机制
- “学习”离散路由注意力
- 以短视频的内存消耗和计算成本生成长视频
- 2.2倍端到端生成加速
Related Work
Long Video Generation
- autoregressive models
- frames, chunks, or segments level (CausVid)
- error accumulation
- uncertain computaional scaling
- diffusion models
- inject controlled noise into historical context (RollingDiffusion and Diffusion Forcing)
- autoregressive denoising (MAGI-1 SkyReels-V2)
- entire past constant-size latent (TTTVideo, FramePack)
only extend to one-minute range due to lossly compression
Long-Context Tuning
- context window: 8 shots ( tokens each)
- quadratic cost of full self-attention – FLOPs and memory scale with
Sparse Attention for Video Generation
- Training-free pruner
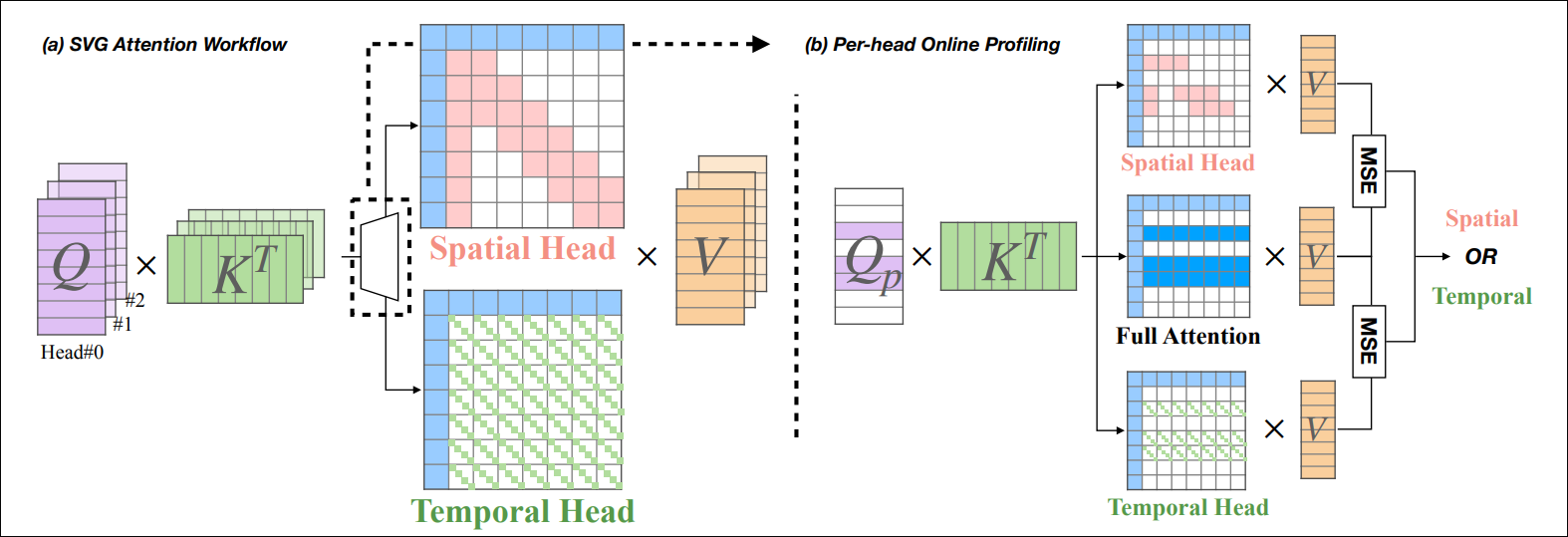
- SparseVideoGen:该方法通过分析注意力头的特性,让不同注意力头动态地专门化为处理空间信息或时间信息,并为每个注意力头选择特定的稀疏模式。这种方法利用了视频中空间和时间信息处理可以分离的特点。
- STA (Sliding Tile Attention):利用视频的局部性特点,将注意力计算限制在局部3D窗口内,以FlashAttention友好的块(tile-by-tile)方式进行操作。这种方法特别适合硬件加速,因为它可以利用现代GPU的并行处理能力。
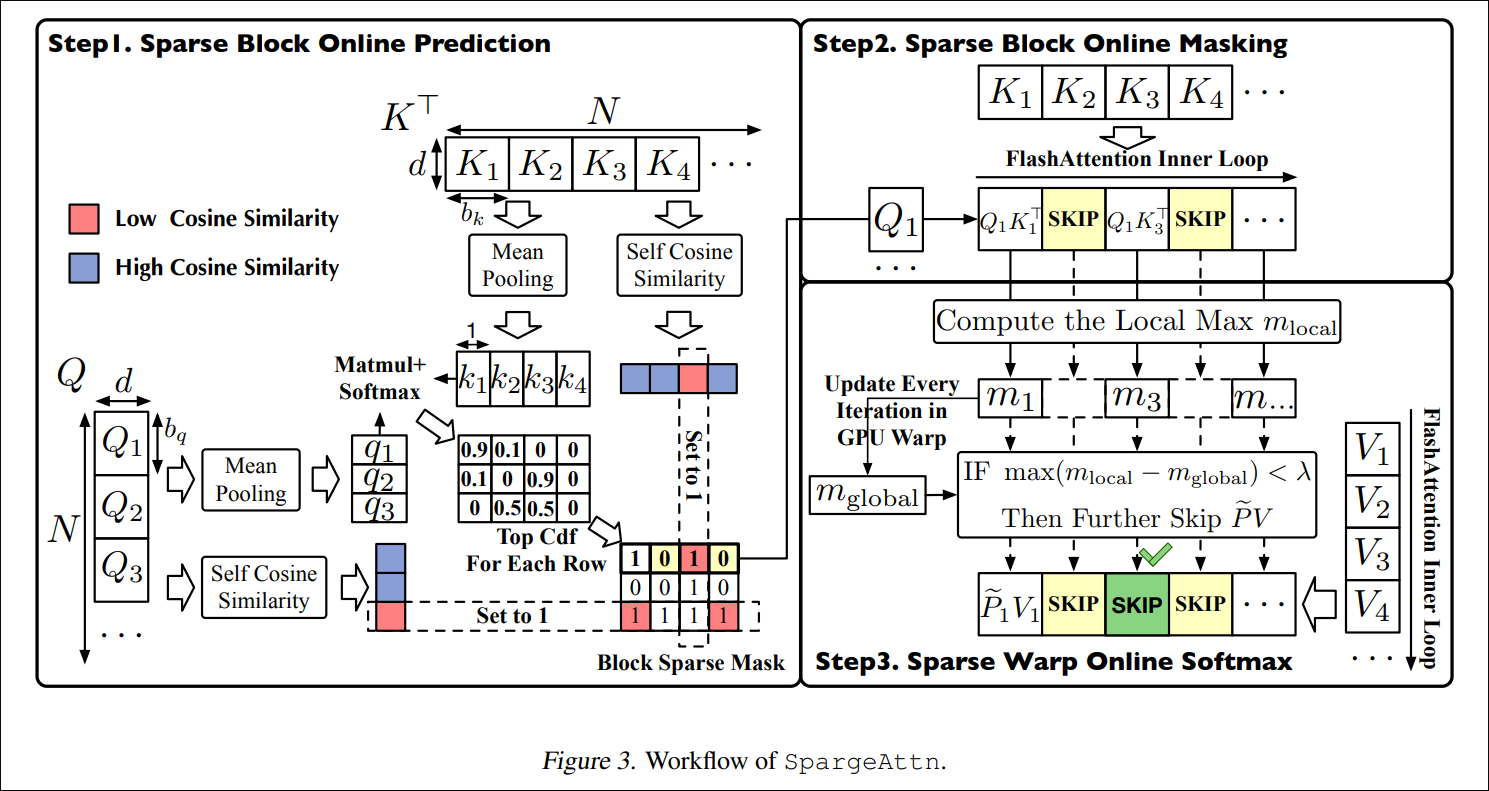
- SpargeAttn/SageAttention:这类方法结合了选择性token压缩和softmax感知的通道,能够采用一定策略跳过QKT/PV计算中不重要的部分。它们通过分析注意力分数的分布,只保留对最终结果有显著贡献的token对。
- AdaSpa:提出了"块化"(blockified)动态稀疏模式,使用Fused LSE-Cached Search技术,可以在不同去噪步骤间重用稀疏索引。这种方法特别适合扩散模型,因为扩散过程中的多个去噪步骤具有相似的注意力模式。
- Jenga:采用无训练的块级注意力雕刻(block-wise attention carving)加上渐进分辨率策略 (早期去噪阶段并不需要高分辨率的潜在变量,而后期阶段则不需要稠密的全注意力机制),在不同分辨率级别上应用不同程度的稀疏化。
- SparseVideoGen:该方法通过分析注意力头的特性,让不同注意力头动态地专门化为处理空间信息或时间信息,并为每个注意力头选择特定的稀疏模式。这种方法利用了视频中空间和时间信息处理可以分离的特点。
- Trainable
- VMoBA (Video Mixture of Block Attention):学习混合块方案,具有层级分区和全局/阈值块选择机制,专门为视频扩散模型(VDMs)设计。该方法在层与层之间动态调整注意力块的分布。
- VSA (Video Sparse Attention):提出硬件高效的粗到细的稀疏内核,可以在训练和推理阶段完全替代全注意力机制。该方法设计时考虑了硬件特性,能更好地利用GPU资源。
- Radial Attention:使用静态的掩码,该掩码源自时空能量衰减(spatiotemporal energy-decay)原理。这种方法假设注意力重要性随着时空距离呈指数衰减,从而创建了一个固定的稀疏模式,能够实现接近全注意力质量的长视频生成。
MoC
- 学习对上下文源进行端到端的精确路由
- 动态选择最相关的上下文块,而非使用固定模式
- 专注于解决长上下文记忆和一致性问题
- 通过因果路由防止循环闭合,确保信息流严格向前
Context Learning in Visual Generation
-
一种用于视频世界模型(例如模拟环境)的框架。
- 引入外部记忆库,将过去的帧及其状态(如相机位姿、时间戳等)存储为“记忆单元”
- 通过记忆检索机制找到与当前场景相关(基于FOV重叠)的历史帧生成未来帧
-
与WORLDMEM思想相近,但专注于交互式长视频生成。
- 将过往生成的历史帧直接作为记忆存储(以原始图像帧形式保存,无需额外的特征提取或3D重建)
- 记忆检索模块:通过比较相机轨迹,选择视野重叠度高的帧作为少量条件帧输入
-
扩散Transformer(DiT)模型本身已经具备一定的“提示上下文”生成能力。核心思想:在训练时让模型同时看到参考图像和目标图像,并通过轻量级微调使模型学会在生成新图像时利用给定的参考图像。
- 多图像拼接输入:将多张条件参考图像与目标图像直接拼接成一个大图像或序列一起提供给扩散Transformer。
- 联合描述训练:为这些成组的图像编写一个联合的文本描述,用自然语言描述每张参考图像与目标图像之间的关系或场景整体。通过这种方式,模型在训练中学会理解和关联多张图像间的语义关系。
- LoRA微调:在不改动原始DiT模型架构的前提下,引入任务特定的LoRA微调。使用少量样本数据(例如每种任务20~100张训练图像)对模型进行低秩微调,使其掌握特定任务(如风格迁移、跨视角一致生成等)的能力。由于LoRA只调整极少量参数,训练开销小但足以激活模型的上下文生成能力。
-
DSD(Diffusion Self-Distillation)关注的问题是如何使预训练的文本到图像扩散模型具备图像+文本条件的生成能力,例如给一张参考图再根据新提示生成保持主体不变的新图像,即“身份/主体保持的生成”。
- 利用扩散模型的上下文生成能力合成数据
- 利用预训练扩散模型本身能够同时生成多张相关图像的能力,来生成包含同一主体的图像网格。
- 借助视觉语言模型(VLM,如CLIP等)对这些生成的图片进行筛选和标注,选出主体一致的成对图像并自动生成描述它们的文本标签。
- 将上一步得到的数据用于训练图像+文本到图像的新模型
- 扩展原先的扩散Transformer架构,使其在输入层接受一张图像(作为条件)和一个文本提示
- 训练模型预测输出图像。要求模型在保持输入参考图像主体特征的前提下,按照文本提示产生对应的目标图像。
- 利用扩散模型的上下文生成能力合成数据
-
传统扩散模型的控制(如ControlNet等)往往需要针对特定类型的条件(草图、深度图、分割等)添加额外网络或大量参数调优。OmniControl提出了一个参数高效、统一的Diffusion Transformer图像控制框架,能够支持多种条件约束的图像生成任务而无需为每种任务设计独立模块
。- 将条件图像的编码集成到原模型的VAE编码器和Transformer块中,仅引入约0.1%的额外参数,充分利用了DiT模型自身的能力
- 采用统一的token序列方式:把条件图像(或其特征)转换成一系列条件token,并与待生成图像的token串联在一起输入Transformer,模型内部的自注意力能够在同一序列中同时关注生成图像和条件信息,实现不同条件任务之间的通用处理
- 动态位置编码机制:针对条件的不同性质,引入可调节的位置编码。对于空间对齐的条件(如分割图或草图),采用与空间位置相关的编码;对于非严格对齐的条件(如参考风格图像),采用另一套规则调整的位置编码
-
FLUX-Context采用流匹配的方法,在统一架构中实现了图像生成和编辑两种能力。
该模型的输入可以同时包含文本和图像(例如一段描述和一张参考图),通过简单的拼接将文本token和图像的潜在表示连接起来送入模型。将生成与编辑统一,在训练时强调语义上下文的保持,所以无论是单次生成还是多次连续编辑,都能更好地保留图像中的主体和关键细节。
Method
Mixture of Contexts
Dynamic Routing via Top-k Selection
: all interested context positions(chunks) for the query
: mean pooled feature of chunk
: relevance score between and context
Context Drop-off and Drop-in
增加 drop-off 和 drop-in 机制,防止过度依赖和无法引入新块。
- ,随机移除个块
- ,随机增加个无关块
Attention Chunking and Routing
Content-aligned Chunking
视频生成的 DiT 是多模态的:空间 、时间、文本 token,而且它们各自带独立的 3D RoPE 因子。所以“相邻索引”在时空上可能隔很远,甚至恰好跨越镜头切换
沿内容边界切分:
- 帧
- 镜头
- 模态(modality stripes)
Fixed Cross-Modal Selection
- explicitly require every visual query token to attend to all text tokens in the sequence (1%)
- facilitate joint gradient propagation into both text and visual embeddings
Fixed Intra-Shot Selection
- explicitly enforce the intra-shot connections
Causality in sparse MoC
- only allow edge with
Computation Efficiency
- 先把 token 按照内容对齐,构造变长集合
- 连 fixed 边
- 对边长集合做 mean pooling,得到每块的 summary
- 使用 head-major order 加速

Experiments
