




EgoTwin: Dreaming Body and View in First Person
Introduction
Introduction

Given a static human pose and an initial scene observation, our goal is to generate synchronized sequences of
egocentric video and human motion, guided by the textual description.
Challenges
Viewpoint Alignment (相机视角对齐头部运动)
Throughout the sequence, the camera trajectory captured in egocentric video must precisely align with the head
trajectory derived from human motion.
Causal Interplay (视频帧对应人体运动)
At each time step, the current visual frame provides spatial context that shapes human motion synthesis; conversely, the
newly generated motion influences subsequent video frames.
e.g. Opening door:
视频帧中的门位置影响下一步的动作(=开门),下一步动作代表身体姿态和摄像头位置如何变化,进而影响视频帧的生成。
Related Work
Video Generation
Methods
- Early Work: Augment UNet-based text-to-image (T2I) models with temporal modeling layers
- Recent Work: Transformer-based architectures
- improved temporal consistency and generation quality.
Camera Control
- Inject camera parameters into pretrained video diffusion models
- rely on known camera trajectories
EgoTwin: not known
- Must maintain consistency with other synthesized content that is strongly correlated to the underlying camera
motion.(自行推断摄像头信息,摄像头强相关内容一致性)
Motion Generation
i.e. Generating realistic and diverse human motions from text.
Methods
- Early Work: Temporal VAE
- Recent Work
- Diffusion models
- operate on continuous vectors, latent space of a VAE or from raw motion sequences
- Autoregressive models
- discretize motion into tokens using vector quantization techniques
- Generative masked models
- hybrid
EgoTwin
- observe the scene only once from the initial human pose
Multimodal Generation
- Others
- Audio-video
- Text and images
- Motion and frame-level language description
- EgoTwin
- Joint modeling of human motion and its corresponding egocentric views
Methodology
Problem Definition
Input
- initial human pose
- egocentric observation
- textual description
Output
- a human pose sequence
- an egocentric view sequence
: number of joints
: number of motion frames
: number of video frames
Framework
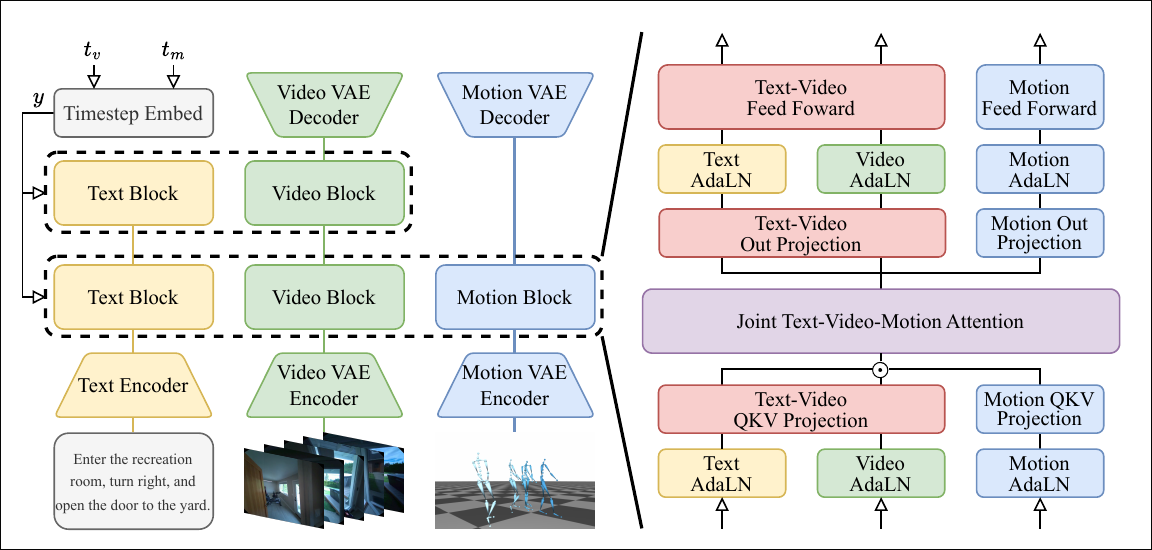
Modal Tokenization
Pose: overparameterized canonical pose representation
i.e.
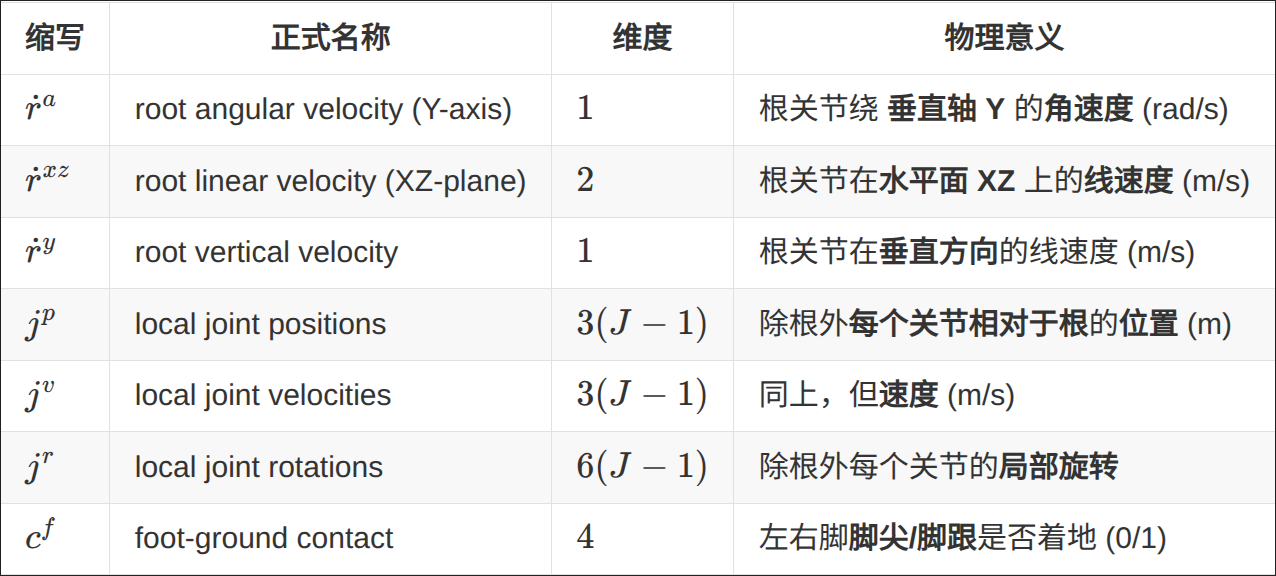
Not suitable for the task
Reason:
Mathematically, recovering the head joint pose requires integrating root velocities to obtain the root pose, then applying forward kinematics (FK) to propagate transformations through the kinematic chain to the head joint.
Too complex!
Head-centric motion representation
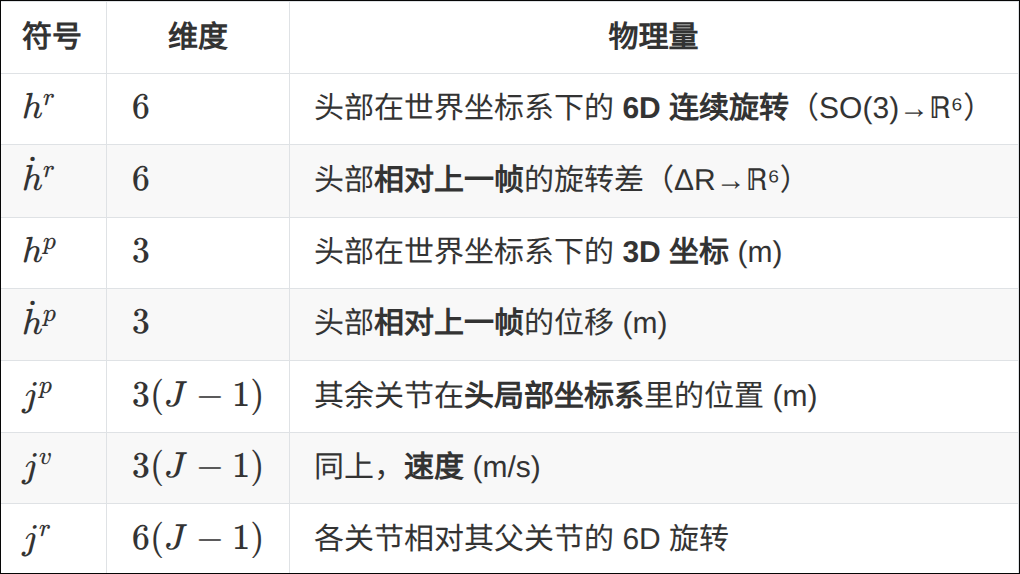
- Explicitly exposes egocentric information
Motion VAE
- Using 1D causal convolutions
- Encoder and decoder symmetrically structured, each comprising two stages of 2× downsampling or upsampling, interleaved
with ResNet blocks
VAE loss separately for the 3D head (), 6D head (), 3D joint (),
and 6D joint () components:
Finally:
Diffusion Transformer
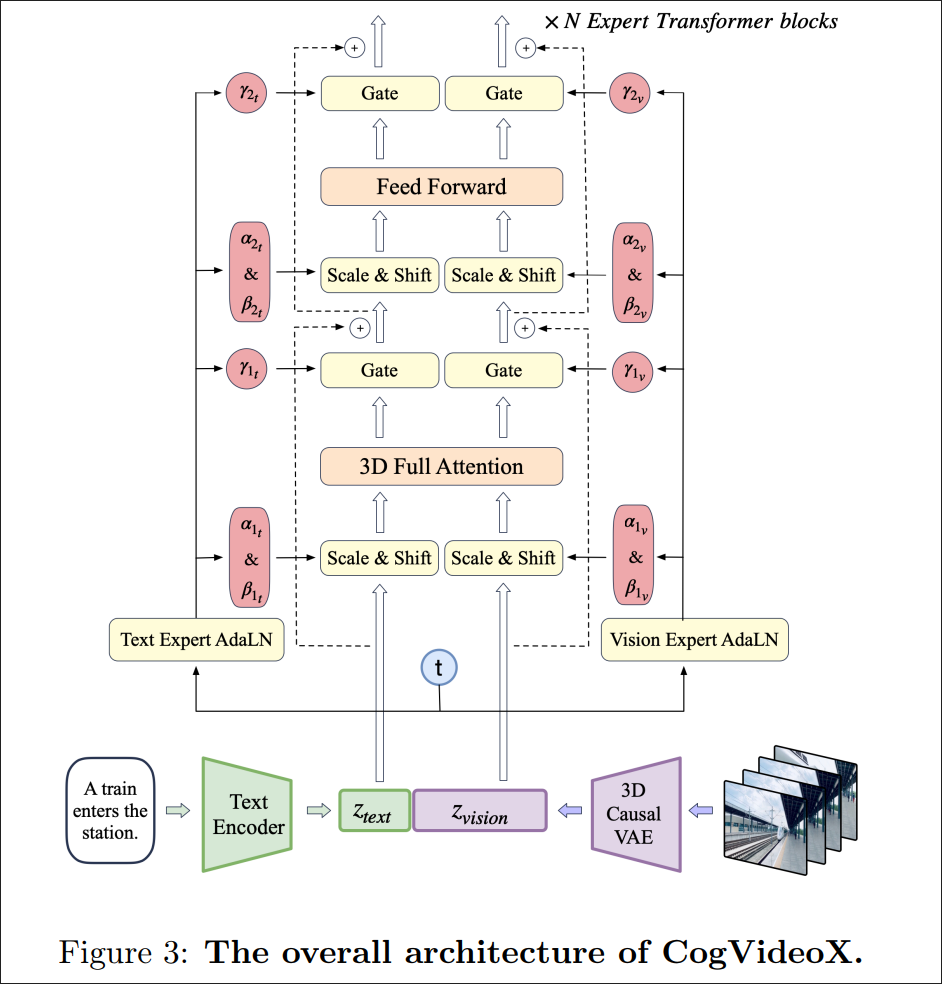
- Text and video branch: CogVideoX (shared weights between text and video)
- Motion: lower-level parts
Interaction Mechanism
Global-level cross-modal consistency
- Sinusoidal positional encodings for both video and motion tokens
- 3D rotary position embeddings (RoPE) for video tokens
Not enough: Each video frame must be temporally aligned with the corresponding motion frame.
Structured joint attention mask
Rewrite as the observation , and
as the (chunked) action , where
Rules:
- 行 → 只能看 (上一动作造成当前观察)
- 列 → 允许看 与 (前后观察决定当前动作)
- 文本 ↔ 任意模态保持全开
- 同模态自注意力全开
- 其余所有跨模态注意力全部阻断

Asynchronous Diffusion
From Kimi:
如果强制 ,就会出现:
- 对运动:每 62.5 ms 就踩一次大步长 → 过度去噪,高频细节(手抖、脚步着地)被抹平;
- 对视频:每 125 ms 才踩一次小步长 → 欠去噪,帧间闪烁、运动模糊。
结论:同一噪声调度在不同帧率下会同时“毒死”两个模态;只有让 独立采样,才能让每种帧率用适合自己的步长。
Video denoiser
Motion denoiser
- : timesteps for video and motion, respectively
- : noised video latent at timestep
- : noised motion latent at timestep
Training
- Stage 1: Motion VAE Training
- Stage 2: T2M Pretraining
- Pretrained on the text-to-motion task using only text and motion embeddings as input
- Omit the much longer video embeddings
- CFG with scale 10%
- Stage 3: Joint Text-Video-Motion Training
- Learn the joint distribution of video and motion conditioned on text
- CFG with scale 10%
Sampling Strategy
CFG for TM2V: